Nowadays, the official NuGet gallery provides very nice looking rendering of a package readme (if provided).
In my opinion, this makes your packages much friendlier to newcomers, and allow you to highlight the various reasons why your library is the one to pick.
Authoring these readmes is straightforward enough for a single package, and can have very comprehensive information, screenshots and samples. For example, see my TableStorage one:
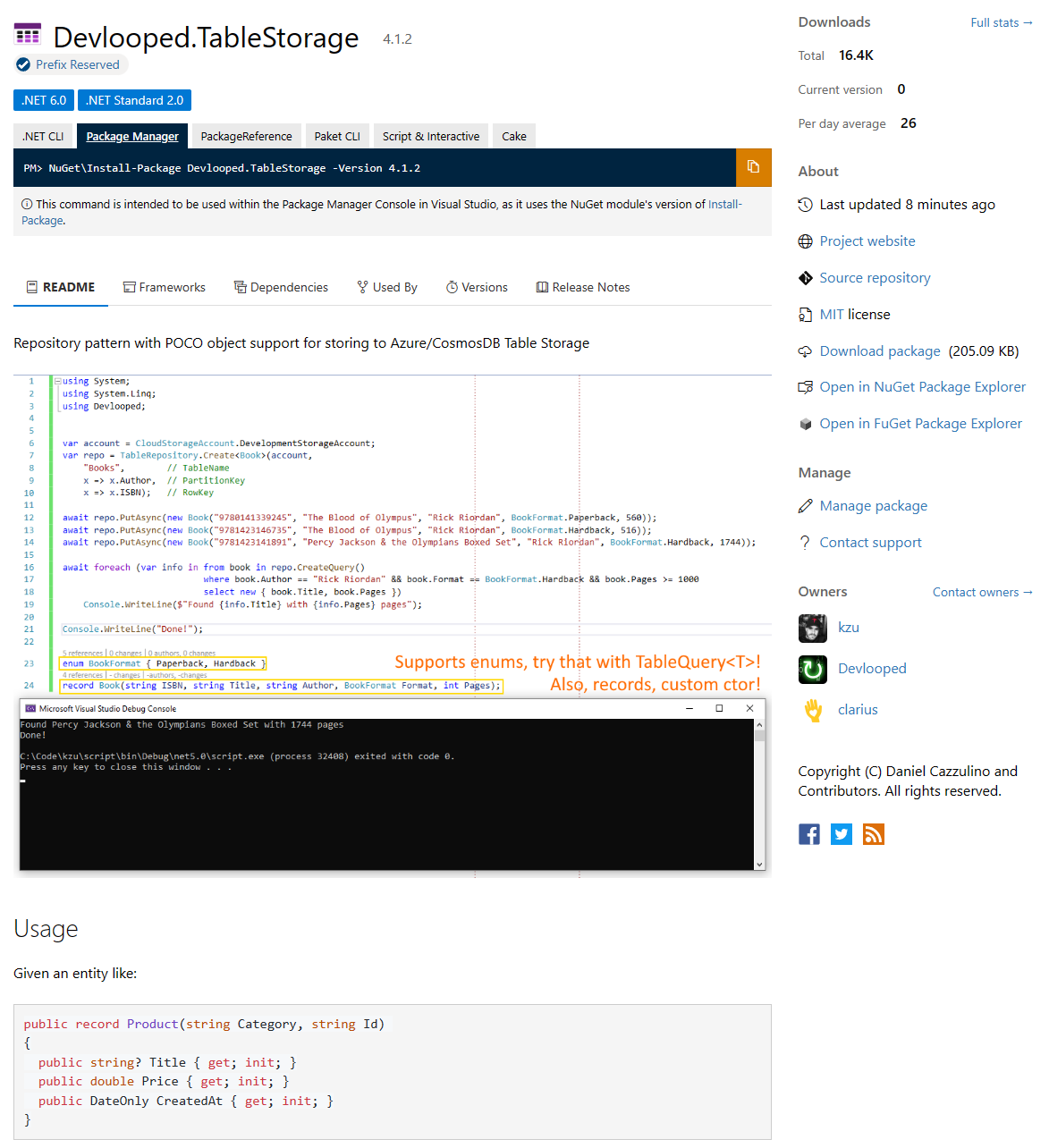
What’s not so great is the experience if you have a bunch of related packages that need to have some common content with minor deltas across them. In the TableStorage project, for example, I produce 5 packages in two flavors each: compiled library and source-only package, totalling 10 packages.
Obviously, maintaining slightly different copies of readme content for all of those would quickly become unmaintainable, leading to likely discourage updating them and leaving them to rot over time.
NuGetizer to the rescue!
Luckily, I’m using nugetizer to pack my project, which has a great feature for package readme: includes!
Here’s an example of a readme using includes that nugetizer understands:
This is the package readme.
<!-- include ../../../readme.md#usage -->
<!-- include ../../../footer.md -->
At packaging time, nugetizer will resolve all includes and expand the contents inline so that the resulting readme contains all the relevant content.
You can include entire files (such as the footer.md above) as well as fragments
of documents as in readme.md#usage. To define these anchors in the readme, you
just use an HTML comment defining the anchor:
<!-- this is readme.md included above -->
# Project Foo
This is a general section on cloning, contributing, CI badges, etc.
<!-- declare the start of the anchor -->
<!-- #usage -->
# Usage
Here we explain our awesome API...
<!-- The optional ending anchor allows to include up to this position -->
<!-- #usage -->
Some additional content we're not including
The fact that the format is an HTML comment is not casual: this means the anchors and include tags aren’t visible when navigating either github.com or nuget.org :).
So let’s see a real usage example!
The TableStorage.Source is the source-only version of TableStorage. You can see that the only difference is a line at the top that states the source-only nature of the former:
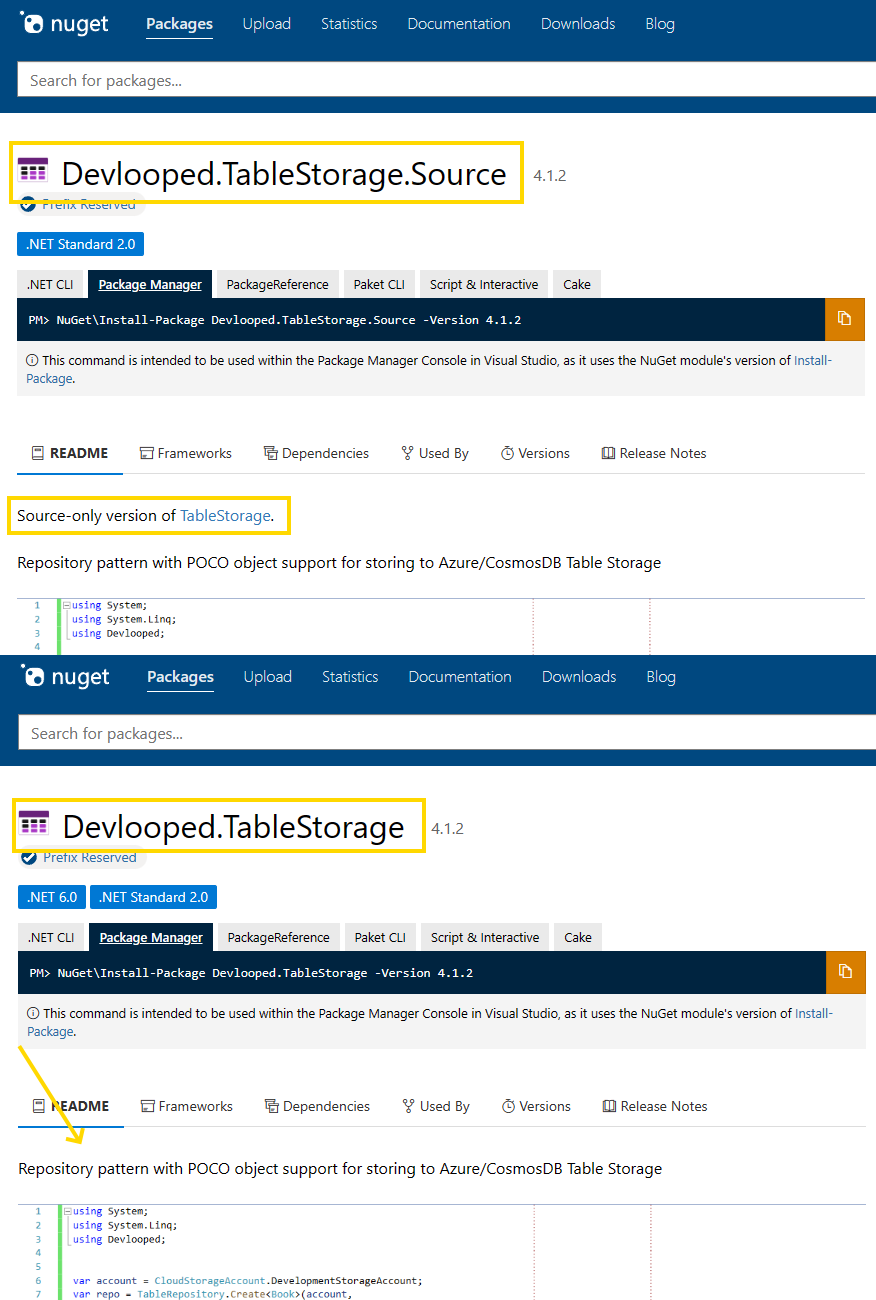
The source-only readme looks like:
Source-only version of [TableStorage](https://www.nuget.org/packages/Devlooped.TableStorage).
<!-- include ../../readme.md#content -->
<!-- include ../../readme.md#sponsors -->
While the library one is:
<!-- include ../../readme.md#content -->
<!-- include ../../readme.md#sponsors -->
Both incorporate sections of the main project readme which separates the project icon/title and badges from the actual content by declaring the anchor like:
 TableStorage
...
<!-- #content -->
Repository pattern with POCO object support for storing to Azure/CosmosDB Table Storage
...
<!-- #content -->
...
<!-- #sponsors -->
Note that in the project readme, there are
installation and
dogfooding
sections between #content and #sponsors, which don’t really belong
in the nuget.org readme, so we don’t include them. The #content anchor has
en ending, whereas the #sponsors doesn’t and so results in the rest of the
file being included.
Auto-inclusion by GitHub action
Now, this looks like a super useful thing to have for your markdown files in the GH repo too, regardless of nuget, right?
For example, I include a Sponsors section at the bottom of all my readmes, to highlight the amazing individual or organizations that support me though my sponsors account. For obvious reasons, I don’t want to be maintaining that across multiple repositories and package readmes, so I keep that bit of markdown centralized (and auto- updated on a schedule) at https://github.com/devlooped/sponsors and include directly from there on each repo readme. For example:
...
<!-- #sponsors -->
<!-- include https://github.com/devlooped/sponsors/raw/main/footer.md -->
Now, since GH doesn’t know what those HTML comments are, they are simply ignored. So we need a way to actually expand the include in CI, but retain the knowledge of the expanded section so that a subsequent update to the upstream file results in an update (and a PR) for it, all happening automatically.
This is the responsibility of the
Resolve File Includes
GitHub action. Its syntax and behavior is kept in sync with nugetizer so
you only have one thing to learn. An example of its usage is at
TableRepository
where I run the markdown include resolving whenever markdown files are
pushed to the main branch:
name: +Mᐁ includes
on:
workflow_dispatch:
push:
branches:
- 'main'
paths:
- '**.md'
- '!changelog.md'
The job’s main work is to checkout and use the action:
jobs:
includes:
runs-on: ubuntu-latest
steps:
...
- name: 🤘 checkout
uses: actions/checkout@v2
- name: +Mᐁ includes
uses: devlooped/actions-include@v1
That will result in changes which you can turn into a PR using the Create Pull Request action or similar.
This could also be run on a schedule, like:
on:
workflow_dispatch:
schedule:
- cron: "0 0 * * *"
You could also just include from an upstream URL directly from the package readme file, and not use the CI-based resolving at all. The resulting content will be the same regardless, since the upstream content is the same.
Including from the main project readme as a slight advantage in that it does not incur a web request per package to bring the external repo content, which should perform better, especially if you have many packages.
Avoid double-processing of package readme
In order to keep the package readme clean (and not resolved by the GitHub action), you can add the following HTML comment at the top or bottom of the file:
<!-- exclude -->
This signals to the action that the file should not be processed. This is simpler than configuring the action instead to exclude particular files, which can also be done via includes/excludes on the action itself:
- name: +Mᐁ includes
uses: devlooped/actions-include@v6
with:
include: [expression]
exclude: [expression]
The syntax follows the Get-ChildItem -Exclude in powershell, which is used to select candidate files as seen in the action source.
My preferred mechanism is to just add <!-- exclude --> at the bottom of my package
readme files.
Closing
I would love for inclusions to be supported out of the box by the readme renderer in GitHub, but if it were, it would necessarily be limited in what you can include (i.e. no arbitrary URLs for safety reasons), so my solution would still be needed, I think.
I deliberately chose a syntax that isn’t XML-y (a simple anchor, no separate
open/close syntax) which is more HTML-y and lax (no ending anchor means include
rest of file). Same for the include tag: after expansion, the is no </include>,
just <!-- [path/url] -->, which is sufficient to locate the range of lines
that were included for efficient replacement when the included content changes.
Hopefully the combination of these two features will encourage you to write more great readmes for your projects and reuse content freely across your packages!
Happy packing :)
/kzu dev↻d