In the .NET ecosystem, there’s been a slow emergence of what I like to call “smart libraries”: these are nuget packages that include additional behavior that “lights up” inside an editor that supports them, such as Visual Studio.
One of the earliest examples is probably xunit, where you’d get helpful squigglies (and build-time errors!) for improper usage of the library, like creating a test theory but not providing any parameters or inline data to it:
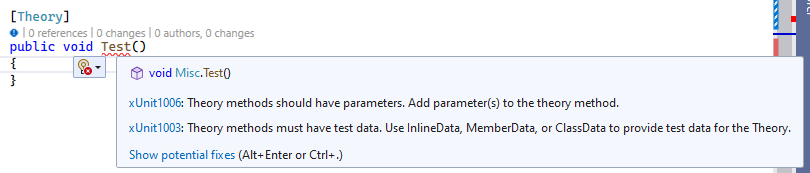
Moreover, if you click the light-bulb (or Alt+Enter or Ctrl+. as shown above for Show
potential fixes), you even get the library to fix the mistake for you!
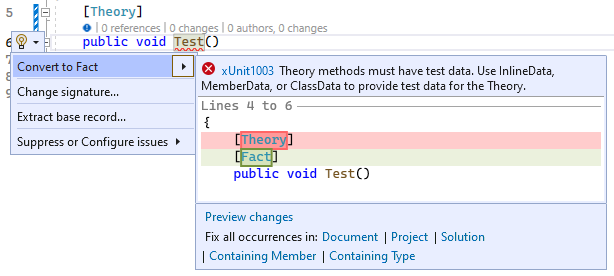
This is all powered by the .NET Compiler Platform SDK, also known as Roslyn. Even authoring Roslyn components (such as code analyzers) is enhanced by the smarts in Roslyn itself:

Let’s dig deeper on what exactly makes a .NET library “smart”.
Analyzers
The docs/learn site on .NET source code analysis contains a comprehensive introduction to what analyzers can do and how they improve your productivity, and also provides some useful links on how to get started so this will be just a quick recap.
Analyzers’ sole purpose is to run during compilation (both at design-time in the IDE as soon as a project is opened, as well as compile-time, either in the IDE or command-line) and report so-called diagnostics (information, warning and errors).
The basic API for creating an analyzer is deceptively simple:
[DiagnosticAnalyzer(LanguageNames.CSharp, LanguageNames.VisualBasic)]
public class MyAnalyzer : DiagnosticAnalyzer
{
public override ImmutableArray<DiagnosticDescriptor> SupportedDiagnostics
=> throw new System.NotImplementedException();
public override void Initialize(AnalysisContext context)
=> throw new System.NotImplementedException();
}
Using the various AnalysisContext.RegisterXXX methods, you get to intercept various stages
during compilation, which gives you a lot of flexibility in detecting and reporting issues or
suggestions based on the project being compiled.
Analyzers are useful in themselves, even if none of the subsequent “levels” of smartness are
provided. But I find that libraries that can offer to fix whatever warnings or errors are
reported, are on a different level in terms of ease of use and learning curve. For example,
the analyzer shown above for diagnostic RS1027 from Roslyn itself, is telling me what needs
fixing, which is quite trivial indeed. So why not offer a pair of code fixes that can do
both things for me? (inherit from DiagnosticAnalyzer or remove the DiagnosticAnalyzerAttribute).
Code Fixes
Code fixes are separated from analyzers since they are only intended for consumption by an IDE/editor and not from the compiler itself. They do so by leveraging the diagnostics reported by an analyzer and providing code fixes for selected ones that can be applied to a document or solution to create a “fixed” solution. Visual Studio does the heavy lifting of showing users a preview of the changes that will be produced, without the code fix author having to do anything other than using the Roslyn syntax APIs to produce modified source code.
In the xunit case shown above, we saw a code fix that modifies the same document where the
diagnostic was reported. This does not always need to be the case. In the following example,
the smart library (Merq in this case) as a generic constraint
on IAsyncCommandHandler<TCommand> that the TCommand must implement IAsyncCommand. Given
a command defined in its own file as:
public record OpenFile(string Path);
A newcomer to the library, would create a handler by following basic intellisense as follows:
public class OpenFileHandler : IAsyncCommandHandler<OpenFile>
{
public bool CanExecute(OpenFile command)
=> throw new NotImplementedException();
public Task ExecuteAsync(OpenFile command, CancellationToken cancellation = default)
=> throw new NotImplementedException();
}
They would be faced with a rather unintuitive compiler error at this point:

The smart library can even offer a much better diagnostic (to boot) than the generic compiler error:

And at this point it can go above and beyond basic compilation errors and empower the user to quickly fix the issue with a code fix that will update the other file containing the command definition:
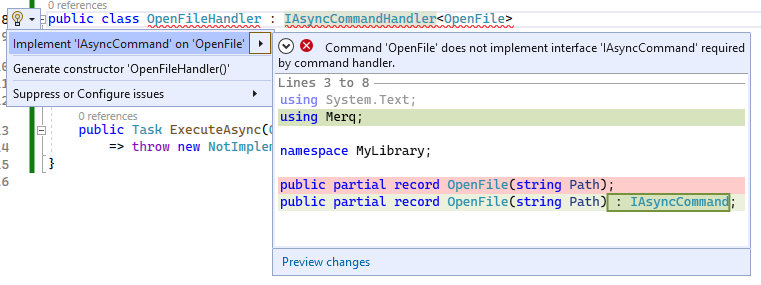
If the user clicks on Preview changes, then can see a detailed view of all files that will be changed by the code fix (there’s no limit to how many files can change by a code fix):
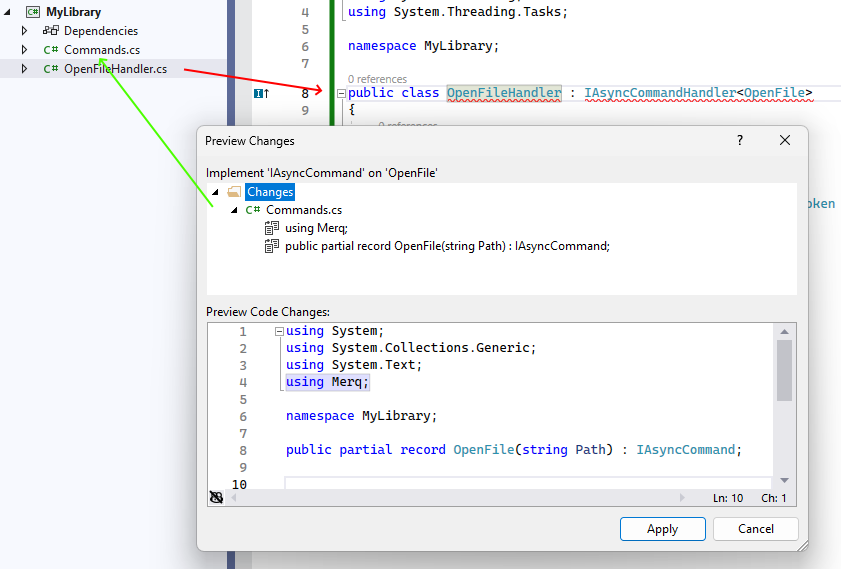
You can see the diagnostic being reported (red arrow) on one file, while the actual fix needs
to be applied to a different file (green arrow). Also note how the fix modified the file in
multiple places, adding a using in addition to implementing the interface required by the
handler implementation.
This can make learning the usage patterns of a new library much more fun and productive.
Source Generators
Source generators emit additional code during compilation, which you can use in your project as if it came from the library (or it was your own code). There are quite a few generators already, as more and more developers are discovering the exciting possibilities they enable for enhanced productivity and usability.
I created the ThisAssembly project, for example, to provide multiple ways to access build-time data from your code, be it assembly information:
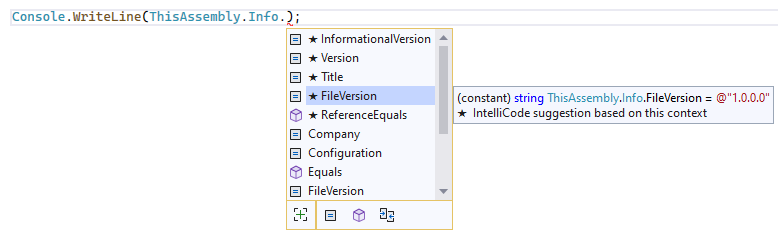
or arbitrary project properties:
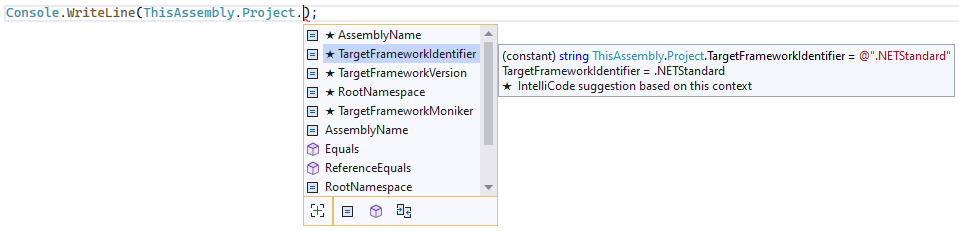
There’s also ThisAssembly.Strings for strong typed access to string resources (including parameterized strings with compile-time safety), arbitrary constants and assembly metadata.
But to grasp the full power that such code generation can provide, consider the
DependencyInjection.Attributed
generator: it allows annotating your types with [Service(ServiceLifetime)] and will
automatically generate an AddServices extension method for IServiceCollection in your
project, which you can use to register all annotated services, with ZERO run-time impact
in performance since it’s basically generating for you all those pesky calls to AddTransient(..),
AddSingleton(...) and so on. That’s a considerable saving in not only typing but also
increased maintainability of your code, since now registration information and desired
lifetime are co-located at the point where the service implementation exists, which is way
easier to find and tweak as needed.
Moreover, in this particular case, the generated registration code is even better that what you’re typically using nowadays :). It’s quite common that given a service with constructor dependencies like:
public class MyService : IMyService
{
public MyService(IOther other, ILogger logger, ...)
}
You will typically register it as:
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddSingleton<IMyService, MyService>();
Which seems fine until you realize that it requires a run-time lookup of the relevant constructor to invoke for instantiation. The generator can instead generate the more optimal (but arguably much harder to maintain and totally boring to code) alternative:
static partial void AddSingletonServices(IServiceCollection services)
{
services.AddSingleton<IMyService>(s =>
new MyService(
s.GetRequiredService<IOther>(),
s.GetRequiredService<ILogger>()));
}
And that partial method is invoked automatically from a single invocation from our startup code:
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddServices();
But how do you package such a thing alongside your library? Behold the NuGetizer!
Packaging
The most common scenario for packaging a smart library, is probably something like:
- A single project containing the library
- Analyzers project
- Code fixes project (these cannot go in the above)
- MSBuild targets (that typically feed information about the project and its items and properties to the analyzers)
It’s also quite common for analyzers or code fixes to depend on additional libraries to perform their work.
Let’s just say that for these fairly common (IMO) requirements, the out of the box nuget packaging experience is quite lacking. I’d go as far as to say it’s quite pointless to try to customize it in any meaningful way: either it does exactly what you need from the very beginning, or switch right-away to the most awesome way to pack in .NET: NuGetizer.
I may be a tiny bit biased, since I’m the main author and maintainer of NuGetizer.
One of my favorite things is the nugetize dotnet (global) tool. You can Install it with dotnet tool install -g dotnet-nugetize (it obviously works only on nugetized projects).
With it, you can very quickly see (and iterate) on the package design without even incurring a full compilation. Here’s the rendering of a project that includes all the mentioned components (main library, analyzers, code fixes, build targets and additional library dependencies):
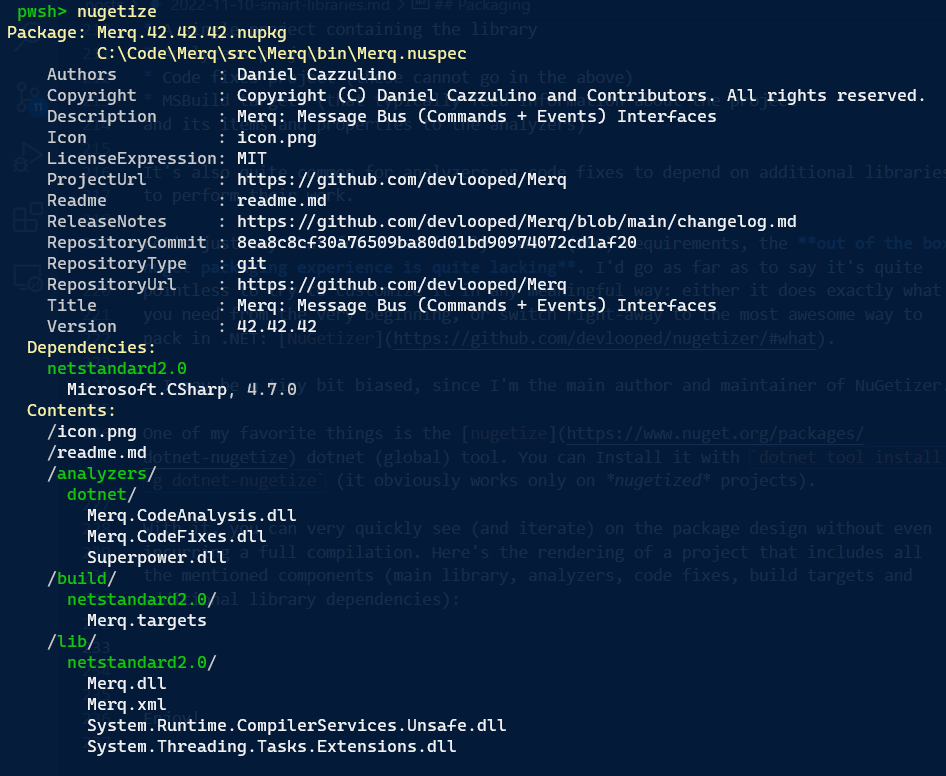
You can see the package metadata at the top, the dependencies (Microsoft.CSharp), package root content for the icon and package readme, both analyzer and code fixes, alongside a third-party library (the awesome superpower parser combinator), the build targets and the main library (and its own run-time dependencies).
It might come as a shock that the entire source for that package does not contain custom targets, weirdly named elements and so on, but is rather straightforward, and is the same .csproj for the library:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netstandard2.0</TargetFramework>
<PackageId>Merq</PackageId>
<Title>Merq: Message Bus (Commands + Events) Interfaces</Title>
<Description>Merq: Message Bus (Commands + Events) Interfaces</Description>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="ThisAssembly.Project" PrivateAssets="all" />
<PackageReference Include="Microsoft.CSharp" />
</ItemGroup>
<ItemGroup>
<ProjectReference Include="..\Merq.CodeAnalysis\Merq.CodeAnalysis.csproj" ReferenceOutputAssembly="false" OutputItemType="Analyzer" />
<ProjectReference Include="..\Merq.CodeFixes\Merq.CodeFixes.csproj" ReferenceOutputAssembly="false" OutputItemType="Analyzer" />
</ItemGroup>
<ItemGroup>
<None Update="Merq.targets" PackFolder="build" />
</ItemGroup>
<ItemGroup>
<InternalsVisibleTo Include="Merq.Tests" />
</ItemGroup>
</Project>
Additional metadata for the package is coming from a Directory.Build.props where you can see the familiar MSBuild nuget pack properties. The project is also using central package management to set versions but also include two common package references, SourceLink and NuGetizer itself.
As you can see, it’s all pretty standard MSBuild all around. Unlike the so-called
SDK Pack, which resorts to intermediate json and nuspec files for everything,
NuGetizer instead implements a first-class project-to-project (P2P) protocol for
communicating what a project contributes. This allows the nugetize CLI tool to
introspect the project purely using MSBuild, but also drives the inclusion of the
artifacts from both
Merq.CodeAnalysis.csproj
and
Merq.CodeFixes.csproj
project references. Both projects are almost identical, with the latter being:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netstandard2.0</TargetFramework>
<PackFolder>analyzers/dotnet</PackFolder>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.CodeAnalysis.CSharp" Pack="false" />
<PackageReference Include="Microsoft.CodeAnalysis.Workspaces.Common" Pack="false" />
<PackageReference Include="PolySharp" Pack="false" />
<PackageReference Include="Superpower" PrivateAssets="all" />
</ItemGroup>
<ItemGroup>
<ProjectReference Include="..\Merq.CodeAnalysis\Merq.CodeAnalysis.csproj" />
</ItemGroup>
</Project>
Here, notice the conspicuous absence of any weird packaging concerns. NuGetizer
implements powerful default heuristics
(than can nevertheless be turned trivially) and consistent properties and item
metadata for packaging. PackFolder, for example, is used as a project property
to denote the default package folder for project artifacts. In the main library,
we also used it to update the package path for a build targets file:
<None Update="Merq.targets" PackFolder="build" />
If you specify a PackFolder, another core item metadata, Pack is automatically
inferred as true for obvious reasons.
When NuGetizer determines contributed artifacts to a package, it will traverse
project and package references that are not marked Pack=false and assume they
contribute to the package. When it finds the analyzer and code fix project references,
it will include the contents they provide in turn. Since they don’t expose their
own package references (by marking them with Pack=false), this project reference
won’t contribute additional dependencies.
PrivateAssets=all is interpreted to mean the same it means for a build: all of
this reference’s artifacts are for exclusive consumption of this project and do
not propagate outside. This is what makes Superpower.dll a part of the
dotnet/analyzer folder and not a dependency for the package. Note, also, how
the PackFolder is not necessary for the package reference: unless otherwise
overridden (like we did for Merq.targets), contributed content defaults to the
package folder defined for the project itself.
Final Thoughts
After authoring and publishing literally hundreds of packages (not all of consistent impact, adoption or even usefulness, obviously ;-)) and witnessing the capabilities available to library authors expand considerably over time, I’m convinced that adding “smarts” to your libraries is almost as important as the API design itself. The generic rules for the language and runtime can only do so much to uncover suboptimal or improper use. Spotting these, offering opportunities for optimization, enhancing productivity and empowering users to better understand (through diagnostics) and fix (via code fixes) issues, can only result in a much more enjoyable experience for your fellow developers consuming your smart library.
Granted, these additions also blur the line between “core” API design and delivery
and developer tooling around it. I personally enjoy doing both, and have been doing
the latter for so long that I actually find this trend quite fascinating. Productivity
through tooling and code generation has always been a passion of mine, going back more
than 17 years when we created the
Microsoft Guidance Automation Extensions and Guidance Automation Toolkit for Visual Studio
2005 and 2008. I just found out it became
OpenGAX and was updated all the
way to VS2015! I created the T4 template engine precursor T3 (yeah, Terminator 3
was from around that time, hehe, hence the name) for that project too, since we
needed to unfold code from more powerful templates than VS provided.
If smart libraries are your first endeavor in developer tooling, fear not: it’s really fun! And you get to work with the latest and greatest of everything always, since tooling is fairly decoupled from library/run-time (i.e. you can have a library with a requirement to target .NET 472, but you can still use the latest & greatest compiler, language features, and IDE to target it).
There are (even more?) interesting times ahead for .NET developers, that’s for sure.
Enjoy!
/kzu dev↻d